-
일기장 검색 기능 만들기HelloJkw 개발 2022. 2. 25. 17:52
사전 지식
- 내 홈페이지는 중간에 크게 바뀌었다.
- RDB를 사용하지 않는다.
- NoSql도 사용하지 않는다.
- Dropbox와 Azure storage를 사용한다.
Cafe24 Linux self hosting 시절
dropbox 동기화를 사용했기 때문에
그냥 local에 있는 파일 전부 읽어서 (메모리에 올려서) 검색했다.
파일이 약 3000 개 쯤 있었는데 병렬로 읽고 SSD였기 때문에 아주 빠르게 검색결과를 반환했다.
검색기능이 전혀 어렵지 않았다.
오히려 검색식을 아주 강력하게 만들었었다.
자세한 내용은 너무 나가기 때문에 생략.
Azure app service에서 검색
동기화 하는 방식이 아니고 파일 하나 읽으려면 rest api하나를 사용해서 읽어와야 한다.
내 일기는 4000 개가 조금 넘는다.
검색 하나 하자고 일기 내용을 전부 읽어오는 것은 말이 안된다고 생각했다.
얼마나 시간이 걸리는지 테스트 해보지도 않았다.
전처리를 해야겠다고 생각한다.
전처리! TRIE
조사 도중 trie라는 것을 알게 됐다.
Trie는 문자열을 효율적으로 탐색하기 위해 만든 트리이다.
만약 "나는 기린 그린 그림을 그렸다." 라는 문장이 있을 때 trie는 다음과 같은 트리를 만든다.
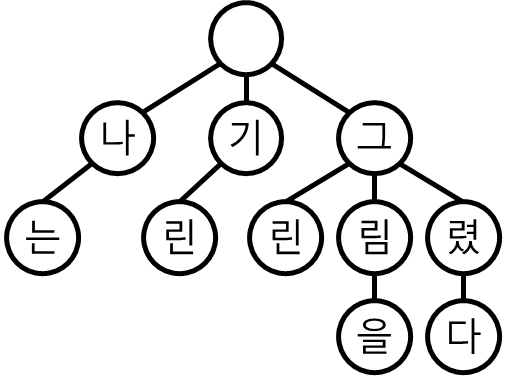
나는 기린 그림을 그렸다 trie 공백을 기준으로 단어를 잘라서 이런 트리를 만들면
"그림" 이라는 단어를 빨리 찾을 수 있다.
"나는 기린 그린 그림을 그렸다" 에서 "그림"이라는 단어를 찾는게 아니라 위 트리에서 찾는것이다.
맨 먼저 첫 글자인 "그" 를 찾고,
"그" 로 시작하는 트리 아래에서 "림"을 찾는다.
"림" 노드에는 여기까지 들어있는 모든 일기 목록을 저장해 놓는다.

"림" 노드에 "그림"이 들어간 일기를 저장해 놓는다. 중간 단어 검색하기
위의 trie는 "림을" 같은 중간 단어 검색이 불가능 하다.
"림"을 root 기준에서 찾아야 하는데 root가 볼 댄 "나", "기", "그" 밖에 없기 때문이다.
그래서 나는 모든 단어를 suffix 로 쪼개서 모두 trie에 넣어서 해결했다.
"나는 기린 그린 그림을 그렸다"는 다음과 같이 쪼개져서 저장된다.
나는
는
기린
린
그린
린
그림을
림을
을
그렸다
렸다
다
이렇게 저장하면 "림을" 같은 중간 단어도 검색할 수 있다.
https://github.com/jkwchunjae/HelloJkwCore/tree/master/HelloJkwCore/ProjectDiary/Search/Trie
용량
가장 큰 걱정은 모든 일기를 하나의 파일로 저장하면 용량이 너무 커지지 않을까 하는 걱정이었다.
다행히 일기 4000 개 인데 trie 용량은 16 MB 정도이다.
이정도면 큰 부담이 아닌 것 같긴 하다.
물론 일기 저장할 때 약간의 딜레이가 생기는데 아직까진 큰 문제는 아닌 듯..
'HelloJkw 개발' 카테고리의 다른 글
Blazor에서 카카오 지도 API 적용하기 (0) 2022.03.05 Blazor에서 typescript 사용하기 (0) 2022.03.04 Blazor에 카카오맵 연동하기 (0) 2022.02.28 Database없이 홈페이지 일기장 구현하기 (0) 2022.02.25 홈페이지를 Blazor로 개발했더니 (0) 2022.02.25